How to achieve Concurrency and Parallelism in Python
Have you ever worked on concurrent programming in Python? If not don't worry. In this tutorial, we are going to differentiate between concurrency and Parallelism in Python, how to achieve them, and get the ability to choose the best approach whenever needed. As Python developers, we have to apply these concepts in real-world scenarios in day-to-day programming life. A better understanding of these concepts will help you to choose the most appropriate way of implementing them for your scenarios.
First, let’s try to understand what does it mean by concurrency and parallelism. After that, we will see how to achieve them in Python.
What are Concurrency and Parallelism in Python?
To explain each of these, we are going to use a task. What does it mean by a task in programming? Simply, we can say a task is a unit of execution that perform operations based on given instructions. Assume we want to execute such 3 tasks.
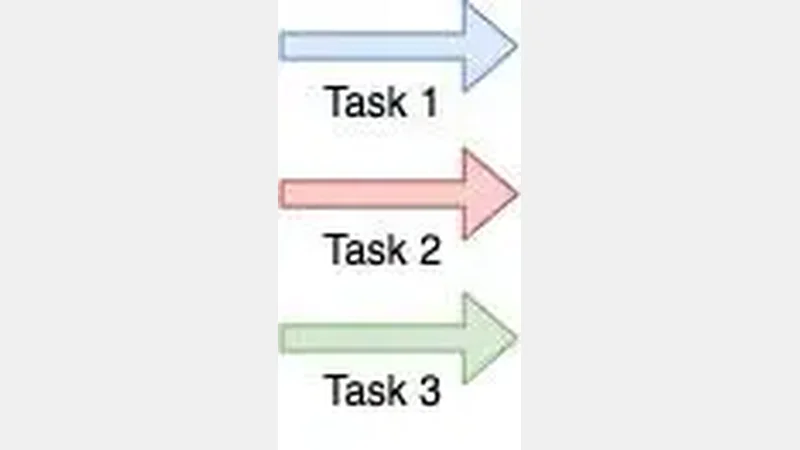 Concurrency and Parallelism in Python - Tasks
Concurrency and Parallelism in Python - Tasks
When the executions of these 3 tasks are interleaved we call it a concurrent execution. In a concurrent execution, each task is executed sequentially one after another.
This is how concurrent execution is happening when there is only one processing unit(Single core).
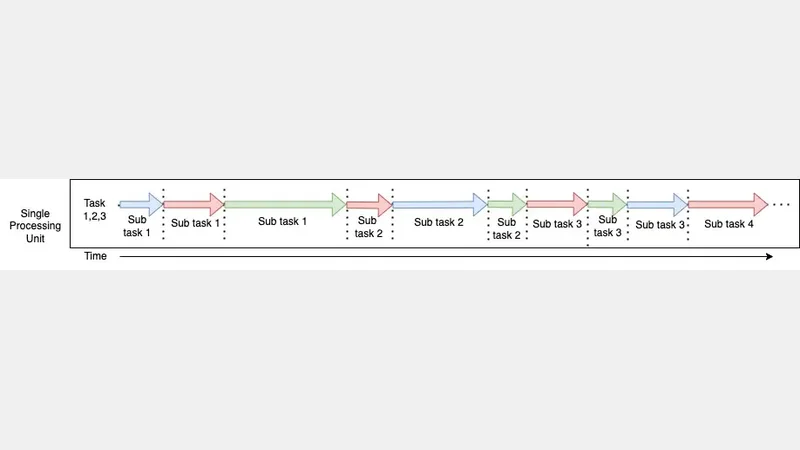 Concurrency and Parallelism in Python - Single Processing
Concurrency and Parallelism in Python - Single Processing
When there is more than one processing unit, concurrent execution can also be in parallel but interleaved, not overlapped. In this case, the executions are concurrent.
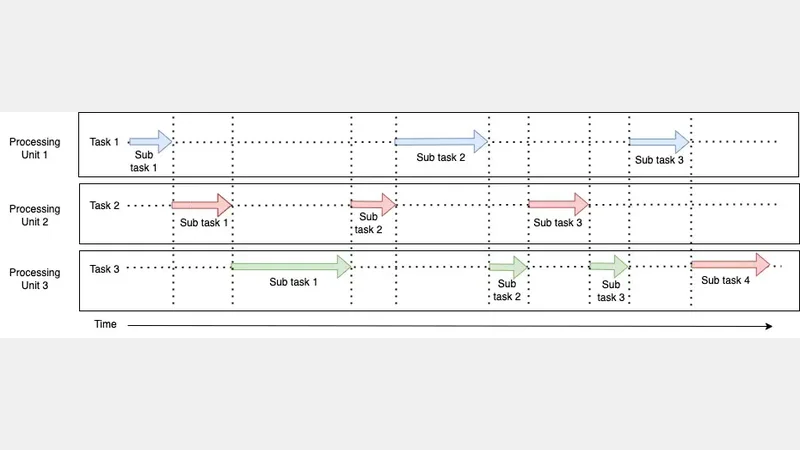 Concurrency and Parallelism in Python - Concurrent Exeuction
Concurrency and Parallelism in Python - Concurrent Exeuction
Parallelism is happening when tasks are actually being executed in parallel. To achieve parallelism we should have more than one processing unit.
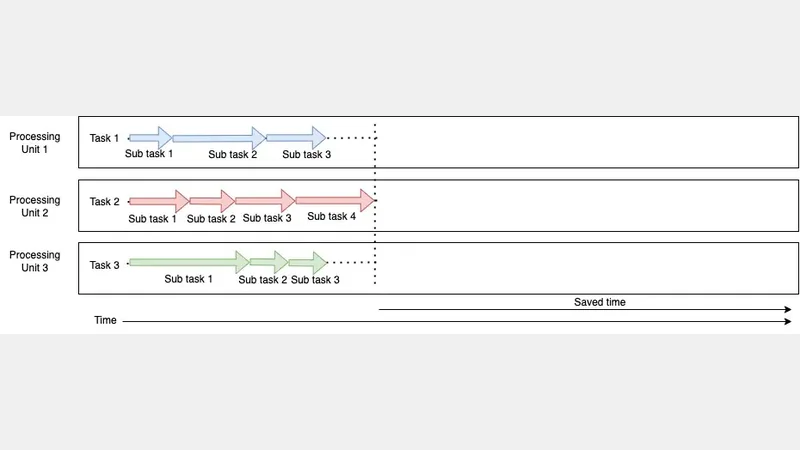 Concurrency and Parallelism in Python - Parallelism
Concurrency and Parallelism in Python - Parallelism
If you check these diagrams carefully, you can see parallelism uses independent processing units(resources) and tasks are being executed at the same time. Concurrency uses shared processing units(resources) and tasks are in progress at the same time. But in concurrency, tasks are not executed at the same time.
| Concurrency | Parallelism |
|---|---|
| * Tasks are not executed at the same time. But Occurring many tasks at the same time(Over a period of time) | * Execute many tasks simultaneously(at a point in time) |
| * Use shared resource | * Use independent resources |
| * ask executions are not overlapped | * Task executions are overlapped |
| * Usually good for IO-bound scenarios. It aggregates waiting time for IO-bound operations | * Usually good for CPU-bound scenarios. It maximizes CPU utilization. |
| * Can be achieved by threading or Asyncio(coroutines or await-async) | * Can be achieved by multiprocessing in python |
How to achieve concurrency and parallelism in Python?
In this section, we are going to see how to achieve concurrency and parallelism in Python. Python gives us several ways to implement concurrency and parallelism. But keep in mind that choosing the correct way depends on the goal(basically IO-bound or CPU-bound) that you want to achieve. Refer to this Python official documentation for more details about Python concurrency.
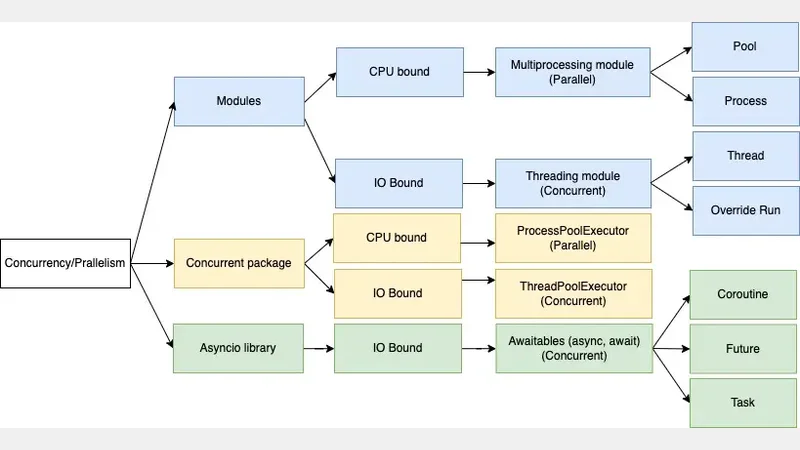 Concurrency and Parallelism in Python
Concurrency and Parallelism in Python
What is the difference between CPU-bound and IO-bound in Python?
A software application that takes longer to interact with IO streams we call an IO-bound application. For example, a program that downloads images from an external website. In this case, the program is waiting to download images. Assume we want to download images from hundred of external websites. Instead of doing it sequentially we can make the waiting time of each request to be overlapped by Python’s IO-bound concurrent mechanisms.
A software application that takes longer to interact with CPU computations we call a CPU-bound application. For example, a search algorithm that searches a given element in a long array. In this case, the program is waiting to solve the problem. Instead of waiting search operation to be completed, we can launch more operations on the rest of the CPUs and make maximum CPU utilization.
Python multiprocessing module
As the above tree diagram shows, multiprocess modules give us several ways to achieve concurrency. In the below sections, we will see how Pool and Process classes do this.
Pool in Python multiprocess
In this example, we are using a Pool object from the multiprocess module. It gives us a convenient way to spawn processes based on multiple inputs.
from multiprocessing import Pool
import os
import time
def bound_cpu(person):
print(f'Hello {person}! Your process id: {os.getpid()}, Your parent process id: {os.getppid()} ' )
if __name__ == "__main__":
st = time.time()
names = ['John', 'James', 'Oliver' ]
bound_cpu("Maxwell")
with Pool() as p:
p.map(bound_cpu, names)
et = time.time()
print(f'Execution time {et-st}')
Result
Hello Maxwell! Your process id: 25514, Your parent process id: 80451
Hello John! Your process id: 25516, Your parent process id: 25514
Hello James! Your process id: 25516, Your parent process id: 25514
Hello Oliver! Your process id: 25516, Your parent process id: 25514
Execution time 0.2228097915649414
As you can see in the result, it creates different subprocesses. But the parent process is the same across all the subprocesses. This is one way to achieve parallelism in Python. Also, the execution time is 0.2228s
Process in Python multiprocess
This code achieves the same goal as the Process class. Even here, it creates different subprocesses and the parent process is the same across all the subprocesses.
from multiprocessing import Process
import os
import time
def bound_cpu(person):
print(f'Hello {person}! Your process id: {os.getpid()}, Your parent process id: {os.getppid()} ' )
if __name__ == "__main__":
st = time.time()
names = ['John', 'James', 'Oliver' ]
process = []
bound_cpu("Maxwell")
for name in names:
proc = Process(target=bound_cpu, args=(name,))
process.append(proc)
proc.start()
for proc in process:
proc.join()
et = time.time()
print(f'Execution time {et-st}')
Result
Hello Maxwell! Your process id: 25444, Your parent process id: 80451
Hello Oliver! Your process id: 25448, Your parent process id: 25444
Hello John! Your process id: 25446, Your parent process id: 25444
Hello James! Your process id: 25447, Your parent process id: 25444
Execution time 0.1238698959350586
Python threading module
Now let’s take a look at several options available in Python’s threading module to achieve concurrency.
Before jumping into details, I must mention GIL (Global Interpreter lock) in Python here. As you may already know, Python doesn’t allow us to execute more than one thread at the same time. Python has a mechanism to lock the current thread unit until the execution is completed. That’s called GIL.
First, we are going to execute a few GET API requests sequentially and see the execution time it will take. After that, we will execute the same API request using threads to check the performance.
Execute APIs requests sequentially
# sequential
import os
import time
import requests
def bound_io(ulr):
res = requests.get(ulr)
print(res.status_code)
if __name__ == "__main__":
st = time.time()
ulrs = [
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',]
for ulr in ulrs:
bound_io(ulr)
et = time.time()
print(f'Execution time {round(et-st, 4)}')
Result
200
200
200
200
200
200
200
200
200
Execution time 3.1808
As you can when running requests sequentially, it took around 3.1808s to complete all the requests.
Create Threads directly in Python threading
Here we are going to create a few Thread objects directly using the treading module. We will pass the target function and URLs as the arguments when creating the Thread objects.
# start method example
from threading import Thread
import os
import time
import requests
def bound_io(ulr):
res = requests.get(ulr)
print(res.status_code)
if __name__ == "__main__":
st = time.time()
ulrs = [
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',]
threads = []
for ulr in ulrs:
thread = Thread(target=bound_io, args=(ulr,))
thread.start()
threads.append(thread)
for t in threads:
t.join()
et = time.time()
print(f'Execution time {round(et-st, 4)}')
Result
200
200
200
200
200
200
200
200
200
Execution time 0.8522
If you look at execution time, it took around 0.8522s to complete all the requests. Now you should be able to understand the advantages of using Treads for such scenarios.
Inherit Thread in Python threading
In this section, we will see another way to implement Threads in Python. Here we will override the run method that is inherited from Python’s Thread class.
# inherit example
from threading import Thread
import os
import time
import requests
def bound_io(ulr):
res = requests.get(ulr)
print(res.status_code)
class ThreadReq(Thread):
def __init__(self, ulr):
Thread.__init__(self)
self.url = ulr
# overrideing run
def run(self):
bound_io(self.url)
if __name__ == "__main__":
st = time.time()
ulrs = [
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',]
threads = []
for ulr in ulrs:
thread = ThreadReq(ulr)
thread.start()
threads.append(thread)
for t in threads:
t.join()
et = time.time()
print(f'Execution time {round(et-st, 4)}')
Result
200
200
200
200
200
200
200
200
200
Execution time 0.5467
Even in this case, it took around 0.5467s.
Python Concurrent package
So far, we have seen how to implement operations concurrently using some Python modules. In this section, we are going to use Python concurrent package to achieve the same goal. The concurrent package gives us high-level interfaces to perform operations concurrently without worrying about the underlying implementation.
How to use ProcessPoolExecutor in Python concurrently?
ProcessPoolExecutor class allows us to perform asynchronous operations using the pool of processes. We will implement the same example that we have done in the Pool section.
from concurrent.futures import ProcessPoolExecutor
import os
import time
def bound_cpu(person):
print(f'Hello {person}! Your process id: {os.getpid()}, Your parent process id: {os.getppid()} ' )
if __name__ == "__main__":
st = time.time()
names = ['John', 'James', 'Oliver' ]
bound_cpu("Maxwell")
with ProcessPoolExecutor() as executor:
executor.map(bound_cpu, names)
et = time.time()
print(f'Execution time {round(et-st, 4)}')
Result
Hello Maxwell! Your process id: 30062, Your parent process id: 80451
Hello John! Your process id: 30064, Your parent process id: 30062
Hello James! Your process id: 30064, Your parent process id: 30062
Hello Oliver! Your process id: 30064, Your parent process id: 30062
Execution time 0.1594
How to use ThreadPoolExecutor in Python parallelism?
ThreadPoolExecutor provides us with a way to perform operations concurrently using a pool of threads.
#threadpoolexecutor
from concurrent.futures import ThreadPoolExecutor
import os
import time
import requests
def bound_io(url):
res = requests.get(url)
print(res.status_code)
if __name__ == "__main__":
st = time.time()
urls = [
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',]
with ThreadPoolExecutor() as executor:
thread = executor.map(bound_io, urls)
et = time.time()
print(f'Execution time {round(et-st, 4)}')
Result
200
200
200
200
200
200
200
200
200
Execution time 0.5988
Python asyncio library
So far we have seen how to achieve concurrent and parallel execution in Python using multiprocess module, threading module, and concurrent package. In this section, we will use the asyncio library to achieve the same.
Asyncio allows us to execute asynchronous, single-thread applications using coroutines.
When we talk about asyncio library, we can’t ignore the event loop because that’s the core of asyncio apps. In other words event loop is the fundamental construct of ansycio There are a number of options available to run the event loop. An event loop does one thing at a time but it can deal with more than one thing at a time. The event loop is a low-level topic in asyncio. As a developer, you can just use high-level APIs available instead of dealing with low-level APIs.
Next, let’s take a look at coroutines in Asyncio and how they allow us to achieve concurrency.
How to use coroutine in asyncio?
What is a coroutine in Python? Check the official definition here.
We will use a high-level API called “run” to execute our coroutine. The run function manages the event loop for us.
#asyncio coroutine
import asyncio
import os
import time
import aiohttp
async def bound_io(session, url):
async with session.get(url) as res:
print(res.status)
async def main():
urls = [
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',]
async with aiohttp.ClientSession() as session:
for url in urls:
await bound_io(session, url)
if __name__ == "__main__":
st = time.time()
asyncio.run(main())
et = time.time()
print(f'Execution time {round(et-st, 4)}')
Result
200
200
200
200
200
200
200
200
200
Execution time 2.3708
We can achieve the same thing by handling the event loop. But it is not necessary.
#asyncio event loop
import asyncio
import os
import time
import aiohttp
async def bound_io(session, url):
async with session.get(url) as res:
print(res.status)
async def main():
urls = [
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',
'https://gorest.co.in/public/v2/users',]
async with aiohttp.ClientSession() as session:
for url in urls:
await bound_io(session, url)
if __name__ == "__main__":
st = time.time()
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
et = time.time()
print(f'Execution time {round(et-st, 4)}')
Result
200
200
200
200
200
200
200
200
200
Execution time 2.5849
Execution summary
These values are just observations and might be different based on several factors. Ex, Internet connectivity, Number of cores, etc
CPU-bound operation summary
| Parallel | Module/Package/Library | Concurrent/Parallel | Time taken(s) |
|---|---|---|---|
| * Pool | * Multiprocess module | * Parellel | * 0.2228 |
| * Process | * Multiprocess module | * Parallel | * 0.1238 |
| * ProcessPoolExecutor | * Concurrent package | * Parallel | * 0.1594 |
IO-bound operation summary
| Sequential | Module/Package/Library | Threading module | Time taken(s) |
|---|---|---|---|
| * Sequential | * NA | * Concurrent/Parallel/Sequential | * 3.1808 |
| * Thread | * Treading module | * Concurrent | * 0.8522 |
| * Override run | * Threadng module | * Concurrent | * 0.5467 |
| * ThreadPoolExecutor * Concurrent package | * Concurrent | * 0.1594 | |
| * Coroutine | * Asincio | * Concurrent | * 2.3708 |
Conclusion
Python has several modules, packages, and libraries to perform operations concurrently/parallel. Each option has pros and cons. I hope this article will help you to choose the best approach.
Comments
There are no comments yet.